Text to Video vs Image to Video: What’s the Difference?

The rapid advancements in artificial intelligence have revolutionized content creation, particularly in the realm of visual media. Among the most exciting innovations are AI-powered video generation tools, which empower users to create dynamic visual narratives with unprecedented ease. Within this burgeoning field, two primary methodologies have emerged: text to video and image to video.
While both aim to produce video content using AI, their underlying mechanisms, input requirements, and optimal use cases differ significantly. Understanding these distinctions is crucial for creators looking to leverage AI effectively to transform their ideas into compelling visual stories. This article will delve into the core differences between text to video and image to video technologies, exploring how each works, their respective strengths and limitations, and when to choose one over the other.
00:00:12 — PREVIEW
See this exact workflow rendered in real time
Skip the manual editing. Lumivids turns a script, image, or idea into a finished video in minutes.
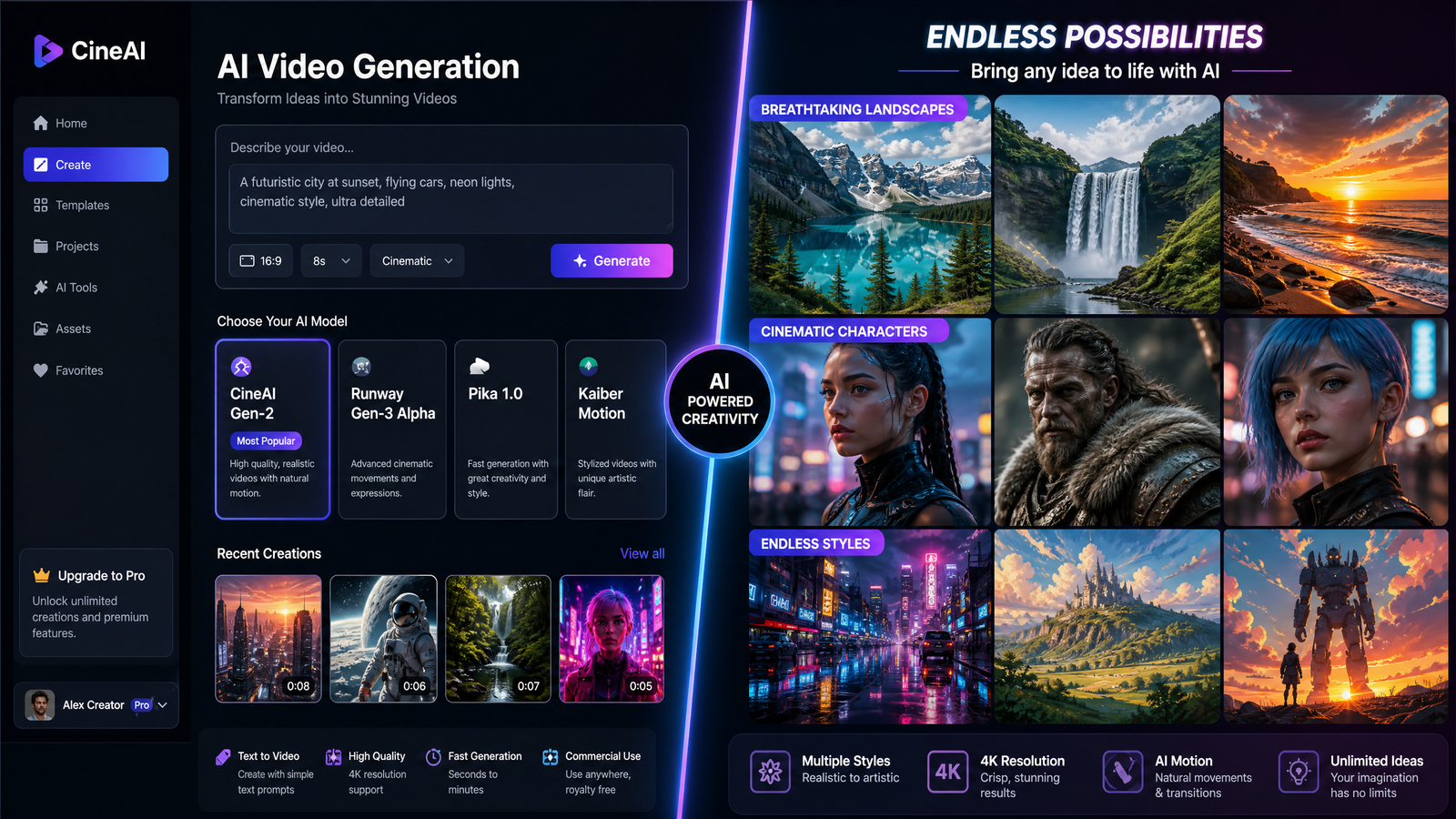
Try it freeUnderstanding AI Video Generation
Before dissecting the differences, it’s important to grasp the fundamental concept of AI video generation. At its heart, AI video generation involves using sophisticated machine learning models to synthesize sequences of images that, when played in succession, create the illusion of motion – a video. These models are trained on vast datasets of videos, learning patterns of movement, object interactions, and temporal coherence. This training enables them to generate new video content that adheres to the learned principles of visual continuity and realism.
The Role of Generative AI in Video
Similar to AI image generators, AI video generation relies heavily on generative AI techniques. These models are designed not just to recognize or classify data, but to create entirely new data that resembles the training examples. For video, this means generating frames that flow naturally from one to the next, maintaining consistency in objects, characters, and environments across time. Diffusion models, which have proven highly effective in image generation, are also increasingly being adapted for video synthesis, often by extending their denoising process into the temporal dimension .
Text to Video: Crafting Narratives from Words
Text to video (T2V) technology allows users to generate video clips purely from textual descriptions. Imagine typing a sentence like “A majestic eagle soaring over snow-capped mountains at sunset,” and an AI model produces a video depicting exactly that scene. This capability represents a significant leap in creative freedom, enabling storytellers, marketers, and educators to visualize concepts without needing pre-existing visual assets.
How Text to Video Works
The process of text to video generation is complex, building upon the principles of text to image generation and adding the crucial element of temporal consistency. Here’s a generalized breakdown:
1.Text Understanding and Scene Decomposition: The AI first analyzes the input text prompt to understand the narrative, objects, actions, and environment described. It often decomposes the prompt into key elements and their relationships, effectively creating a conceptual storyboard or scene graph.
2.Initial Frame Generation: Similar to text to image, the model generates an initial set of frames or a keyframe that represents the core visual elements of the prompt. This might involve translating the textual description into a visual representation of the main subject and background.
3.Temporal Coherence and Motion Synthesis: This is where T2V diverges significantly from T2I. The model must then generate subsequent frames, ensuring that objects move realistically, lighting remains consistent, and the overall scene evolves coherently over time. This often involves:
- Motion Dynamics: Predicting how objects and characters should move based on the prompt (e.g., an eagle soaring implies a specific type of flight path and wing movement).
- Frame Interpolation and Prediction: Generating intermediate frames to create smooth transitions and continuous motion between keyframes. This can involve predicting future frames based on past ones or interpolating between existing frames.
- 3D Scene Understanding (Advanced Models): Some advanced T2V models might construct an internal 3D representation of the scene, allowing for more consistent object placement, camera movements, and lighting across frames.
4.Refinement and Post-processing: The generated video frames are then refined to enhance visual quality, ensure consistency, and remove any artifacts. This can involve super-resolution techniques, color correction, and temporal smoothing.
Strengths of Text to Video
- Purely Generative: Creates video content from scratch, requiring no initial visual assets. This is ideal for conceptualization and bringing abstract ideas to life.
- Creative Freedom: Offers immense creative flexibility, allowing users to describe virtually any scene or action.
- Storytelling Focus: Excellent for narrative creation, storyboarding, and generating unique visual content for scripts or ideas.
Limitations of Text to Video
- Complexity and Control: Achieving precise control over every detail of the generated video can be challenging. Subtle nuances in motion, character expressions, or specific object interactions might be difficult to convey through text alone.
- Computational Intensity: Generating high-quality, coherent video from text is computationally very demanding, often requiring significant processing power and time.
- Coherence and Consistency: Maintaining perfect temporal coherence and avoiding visual glitches or inconsistencies across longer video clips remains a significant challenge for current models.

Image to video: Animating Still Visuals
Image to video (I2V) technology, in contrast, takes one or more existing still images as input and animates them or generates video sequences based on them. This approach is particularly useful when you already have a visual foundation – a photograph, an illustration, or a design – and you want to bring it to life with motion. Common applications include animating characters from a single image, adding dynamic camera movements to a static scene, or generating short, looping video clips from a still picture.
How Image to video Works
Image to video generation leverages the content of the input image(s) as a primary reference, focusing on introducing motion and temporal evolution. The process typically involves:
1.Image Analysis and Feature Extraction: The AI model analyzes the input image to understand its content, depth, objects, and potential for motion. It extracts key features and creates a detailed representation of the static scene.
2.Motion Guidance (Text Prompt or Implicit): Motion can be guided either by a text prompt (e.g., “make the character wave their hand”) or implicitly by the model’s understanding of natural movement patterns. Some I2V models might infer motion based on the image content itself, such as animating a person walking if the image depicts them in a walking pose.
3.Motion Synthesis and Frame Generation: The core of I2V involves generating a sequence of frames where the elements of the input image are animated. This can be achieved through various techniques:
- Object-Specific Animation: Identifying objects within the image and applying learned motion patterns to them (e.g., making a tree sway, a person’s hair blow in the wind).
- Camera Movement Simulation: Generating frames that simulate camera pans, zooms, or rotations across the static image, creating a dynamic feel.
- Deformation and Morphing: Gradually deforming parts of the image to create subtle movements or transformations.
- Diffusion-based Animation: Similar to T2V, diffusion models can be used to add noise to the input image and then denoise it into a video sequence, guided by the original image and desired motion .
4.Temporal Smoothing and Consistency: Ensuring that the generated motion is smooth, realistic, and consistent across the video frames, avoiding abrupt changes or visual artifacts.
Strengths of Image to video
- Content Preservation: Excellent for maintaining the core visual identity and details of an existing image while adding motion.
- Efficiency for Existing Assets: Ideal when you already have high-quality images and want to quickly convert them into dynamic video content.
- Controlled Animation: Often offers more direct control over the animation of specific elements within the image, especially with explicit motion prompts.
- Resource Efficiency: Can be less computationally intensive than T2V for generating short, focused animations, as it starts with a strong visual reference.
Limitations of Image to video
- Limited Scene Changes: Typically struggles with generating entirely new scenes or significant environmental changes beyond what is present in the original image.
- Creativity Constrained by Input: The output is inherently tied to the input image, limiting the scope for entirely novel creative interpretations.
- Potential for Artifacts: Complex animations or significant transformations can sometimes lead to visual distortions or unnatural movements if the model struggles to interpret the image’s 3D structure or occlusions.
Key Differences: A Comparative Overview
To summarize, the fundamental distinction between text to video and image to video lies in their starting point and the nature of their generative process. The table below highlights these key differences:
| Feature | Text to Video (T2V) | Image to video (I2V) |
| Primary Input | Textual description/prompt | One or more existing still images (optional text prompt) |
| Starting Point | Blank canvas; generates content from conceptual understanding | Existing visual asset; animates or transforms it |
| Creative Scope | High; can create entirely new scenes and concepts | Moderate; constrained by the content of the input image |
| Control Level | Abstract; guided by textual descriptions | More direct; focuses on animating specific elements of the image |
| Complexity | High; requires generating both content and motion | Moderate; primarily focuses on generating motion and transformation |
| Use Cases | Storyboarding, conceptualization, generating unique narratives, bringing abstract ideas to life | Animating static images, adding camera movements, creating short loops, enhancing existing visuals |
| Computational Cost | Generally higher, especially for longer, complex videos | Generally lower for focused animations, but can increase with complexity |
| Output | Entirely new video content | Animated or transformed version of the input image |
When to Use Which?
The choice between text to video and image to video largely depends on your creative goals, available assets, and desired level of control:
- Choose Text to Video when:
- You have a clear narrative or concept but no existing visual assets.
- You want to explore entirely new scenes, characters, or environments.
- You prioritize creative freedom and the ability to generate unique content from scratch.
- You are in the early stages of content creation, such as storyboarding or conceptual design.
- Choose Image to video when:
- You already have high-quality images (photos, illustrations, designs) that you want to animate.
- You need to add dynamic motion or camera movements to static visuals.
- You want to create variations or stylistic transformations of an existing image.
- You are looking for a more controlled way to animate specific elements within a scene.
- You need to quickly generate short, engaging video clips from still assets for social media or marketing.
The Future of AI Video Generation
Both text to video and image to video technologies are evolving at a rapid pace. Future developments are likely to see increased integration between the two, allowing for more seamless workflows where users can generate initial concepts from text and then refine and animate them using image-based controls. We can also expect improvements in:
- Fidelity and Realism: Generating videos that are indistinguishable from real footage.
- Longer Video Generation: Overcoming challenges in maintaining coherence and consistency over extended video durations.
- Real-time Generation: Reducing the computational time required to generate videos, enabling more interactive and dynamic creative processes.
- Multimodal Inputs: Combining text, images, audio, and even 3D models as inputs to create richer and more complex video outputs.
- Ethical AI: Addressing concerns related to bias, misinformation, and copyright in AI-generated content.
Conclusion
Text to video and image to video represent two powerful, yet distinct, approaches to AI-powered video generation. While text to video excels at bringing abstract narratives to life from words alone, image to video shines in animating and transforming existing visual assets. Understanding their unique strengths and limitations allows creators to make informed decisions, harnessing the full potential of AI to produce captivating and innovative video content. As these technologies continue to mature, they will undoubtedly reshape the landscape of digital media, offering unprecedented tools for visual storytelling and creative expression.
References
RENDER COMPLETE
Ready to make your own?
Join the creators already producing video at a scale traditional production can’t match.







Post Comment